


AI


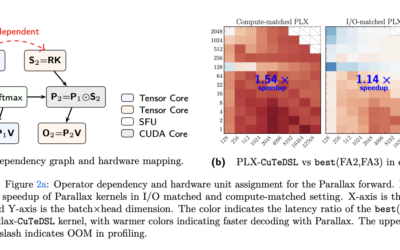
Parallax: A Parameterized Local Linear Attention That Keeps Softmax and Adds a Learned Covariance Correction Branch
The Transformer’s attention mechanism has barely changed since 2017. Most efficiency work has tried to replace softmax attention outright. A new paper takes a different...
A Developer’s Guide to Systematic Prompting: Mastering Negative Constraints, Structured JSON Outputs, and Multi-Hypothesis Verbalized Sampling
Most developers treat prompting as an afterthought—write something reasonable, observe the output, and iterate if needed. That approach works until reliability becomes critical. As LLMs...

RightNow AI Releases AutoKernel: An Open-Source Framework that Applies an Autonomous Agent Loop to GPU Kernel Optimization for Arbitrary PyTorch Models
Writing fast GPU code is one of the most grueling specializations in machine learning engineering. Researchers from RightNow AI want to automate it entirely. The...

The ‘Bayesian’ Upgrade: Why Google AI’s New Teaching Method is the Key to LLM Reasoning
Large Language Models (LLMs) are the world’s best mimics, but when it comes to the cold, hard logic of updating beliefs based on new evidence,...

Meet OAT: The New Action Tokenizer Bringing LLM-Style Scaling and Flexible, Anytime Inference to the Robotics World
Robots are entering their GPT-3 era. For years, researchers have tried to train robots using the same autoregressive (AR) models...
- .apr-fig { text-align: center; margin: 1.35em 0; line-height: 1.4; } .apr-fig–wide img { display: inline-block; width: 100%; max-width: 100%; height: […]
- .grasp-results-table table { font-size: 0.875rem; line-height: 1.35; width: 100%; } .grasp-results-table th, .grasp-results-table td { padding: 0.35rem 0.5rem; } /* […]
- Understanding the behavior of complex machine learning systems, particularly Large Language Models (LLMs), is a critical challenge in modern artificial […]
- An encoder (optical system) maps objects to noiseless images, which noise corrupts into measurements. Our information estimator uses only these […]
- In this post, I’ll introduce a reinforcement learning (RL) algorithm based on an “alternative” paradigm: divide and conquer. Unlike traditional […]
- What exactly does word2vec learn, and how? Answering this question amounts to understanding representation learning in a minimal yet interesting […]
- .modal { display: none; position: fixed; z-index: 9999; padding-top: 50px; left: 0; top: 0; width: 100%; height: 100%; overflow: auto; […]
- Recent advances in Large Language Models (LLMs) enable exciting LLM-integrated applications. However, as LLMs have improved, so have the attacks […]
- PLAID is a multimodal generative model that simultaneously generates protein 1D sequence and 3D structure, by learning the latent space […]
- Training Diffusion Models with Reinforcement Learning We deployed 100 reinforcement learning (RL)-controlled cars into rush-hour highway traffic to smooth congestion […]